该网页主要介绍了名为AlphaPy的机器学习框架:
- 框架概述
- 是面向投机者和数据科学家的机器学习框架,用Python编写,结合了
scikit-learn、pandas等库,可用于多种任务,如运行机器学习模型、分析市场、预测体育赛事、开发交易系统和分析投资组合等。 - 包含
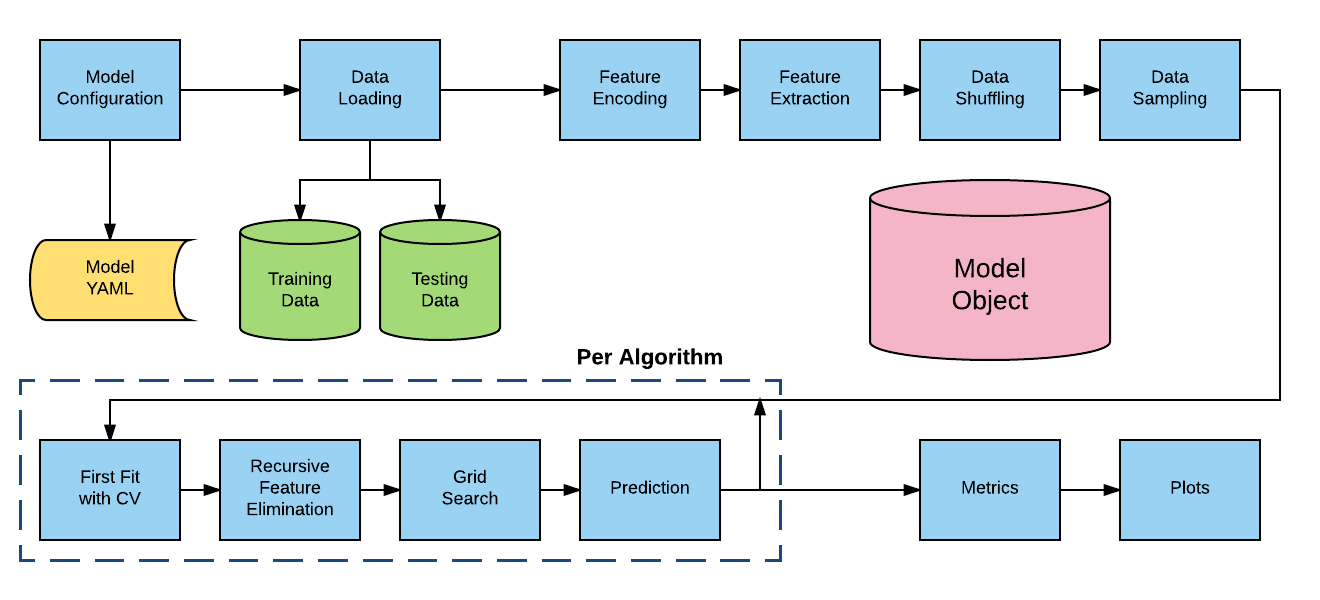
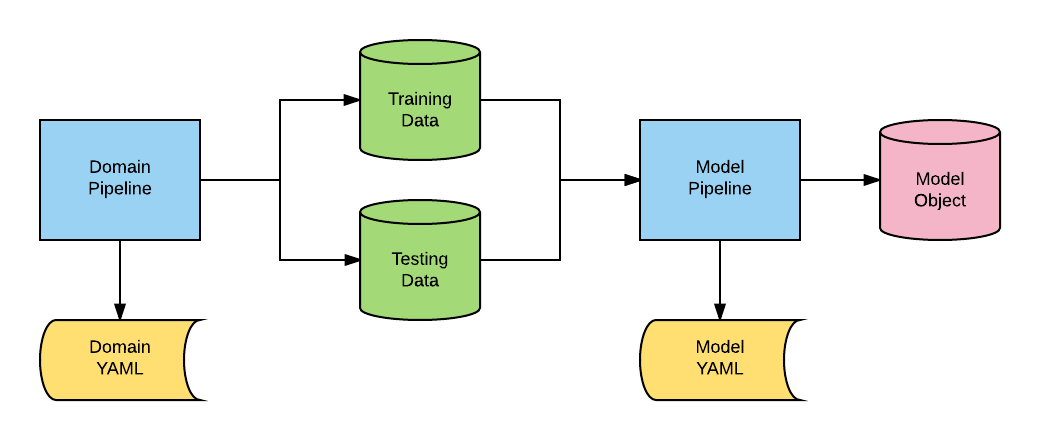
alphapy基础包以及在其之上运行的领域管道MarketFlow(mflow)和SportFlow(sflow),将领域管道和模型管道分离,领域管道负责将原始数据转换为规范形式(训练集和测试集),模型管道用于处理各种项目且在多次Kaggle竞赛中得到发展。 - 框架组件
- 领域管道(Domain Pipeline):通过Python代码创建标准训练和测试数据,如组合不同数据框或收集外部时间序列数据,并转换后输入模型管道。
- 领域YAML(Domain YAML):使用YAML编写的配置文件,为数据科学家提供灵活性,每个领域或应用通常有标准模板。
- 训练数据(Training Data):作为外部文件以
pandas数据框形式读取,分类任务中某列代表目标或因变量。 - 测试数据(Testing Data):同样以
pandas数据框形式读取的外部文件,分类时标签可能包含也可能不包含。 - 模型管道(Model Pipeline):通用的Python代码,用于运行所有分类或回归模型,从数据开始到生成用于新预测的模型对象结束。
- 模型YAML(Model YAML):控制模型管道运行的配置文件,创建模型的各个方面都通过该文件控制。
- 模型对象(Model Object):所有模型保存到磁盘,可在评分模式下加载并在新数据上运行。
- 核心功能
- 主要用于监督学习任务,可生成二元分类(将元素分为两组)、多类分类(分为多个类别)和回归(根据导出系数预测实值)模型。
- 分类算法包括AdaBoost、Extra Trees等多种;回归算法有Extra Trees、Gradient Boosting等。
- 外部依赖包:在模型和领域管道中依赖一些关键包,如
categorical-encoding、imbalanced-learn、pyfolio、XGBoost等,多数不在Anaconda Python平台中,需参考网络或Github获取更多信息。
从当前仓库的文件结构和部分代码来看,这个仓库主要是一个名为 alphapy 的项目,以下是一些可能的主要功能和特性:
1. 核心类与对象管理
System类:- 功能:用于创建新的交易系统,每个系统有唯一的名称,存储在
System.systems这个类变量中。 - 特性:支持设置长头寸入场条件、短头寸入场条件、长头寸出场条件、短头寸出场条件、持仓周期和是否加仓等。
- 功能:用于创建新的交易系统,每个系统有唯一的名称,存储在
Portfolio类:- 功能:创建具有唯一名称的投资组合,所有投资组合存储在
Portfolio.portfolios中。 - 特性:可以设置投资组合的分组名称、标签、命名空间、最大持仓数、持仓计算依据、踢出仓位数量、踢出标准、是否限制持仓、权重计算依据、起始资金、保证金比例、最小现金比例、固定仓位比例、最大损失比例等。
- 功能:创建具有唯一名称的投资组合,所有投资组合存储在
Trade类:- 功能:用于发起一笔交易。
- 特性:记录交易的名称、交易订单类型、交易数量、交易价格和交易时间。
2. 数据处理与存储
np_store_data函数:- 功能:将 NumPy 数据存储到文件中。
- 特性:支持指定存储目录、文件名、文件扩展名和字段分隔符。
3. 模型相关
load_predictor函数:- 功能:从存储中加载模型预测器,默认加载最新的模型。
- 特性:支持从
.pkl或.h5文件中加载模型预测器。
4. 环境配置
environment.yml文件:- 功能:定义项目的运行环境依赖。
- 特性:指定了项目所需的各种 Python 库及其版本,包括数据处理(如
pandas、numpy)、机器学习(如scikit-learn、tensorflow)、可视化(如matplotlib、seaborn)等方面的库。
5. 文档与项目管理
docs文件夹:- 功能:存放项目的文档相关文件,如
Makefile、conf.py等,用于生成项目文档。
- 功能:存放项目的文档相关文件,如
.gitignore、.travis.yml等文件:- 功能:用于项目的版本控制和持续集成配置。
总体来说,这个仓库可能是一个用于量化交易或金融分析的项目,包含了交易系统管理、投资组合管理、数据处理、模型加载等功能。